

Decreasing Uniformity : Neuralink Compression Challenge Submission
Decreasing Uniformity : Neuralink Compression Challenge Submission
Our winning solution for the Neuralink Compression Challenge

Background
Sometimes a challenge is so easy that it stirs disbelief. At first glance, Neuralink’s Compression Challenge appears quite tame: beat ZIP at compressing 743 audio files. However, beneath the surface lies an interesting conclusion: Neuralink’s brain data is so random that their (hilariously well-compensated) programmers sought assistance from ✨internet math autists✨.
In our past article, we introduced Uniformity, an entropy measure designed to replace Shannon entropy, specifically when manipulating the Neuralink corpus.
For the AI-bros, our uniformity measure is analogous to a loss function designed for the Neuralink dataset.
In this article, we showcase a custom data compressor built on top of our uniformity measure. We outperform zip by ~100,000 bytes while working in realtime (~0.02 seconds) per file

Introduction
Our original approach was rooted in naivety. During a 40-hour coding binge, we built (in pure C) a markov chain and a byte-level arithmetic coder for the Neuralink dataset. For those readers familiar with data compressors and eager for the punchline, here it is: Markov chains, and by extension, neural networks could not outperform ZIP on the Neuralink dataset. The distribution of audio samples in the corpus was noisy, and long-term dependencies were notably absent.

For the noobs, here’s the TL;DR: We wasted 40 hours reinventing the LZMA compression algorithm. 5 minutes with Linux’s in-built 7Zip utility would prove futile our initial approach.
Naturally, a comparison of different data compression utilites was needed. Bzip2 performed best on an arbitrarily chosen file. 7Zip came second and zip/gzip performed worst. Our Twitter mutuals had come to this conclusion.

And so, we hit an impasse. Should we double down on Bzip2 - perhaps write a custom Burrows-Wheeler + Move-to-Front transform combo? Or should we devise something entirely different?
What did we know that the Neuralink engineers didn’t?
Four things.
The inventor of Gzip asserts, ‘You can compress already compressed data’. From our time building data compressors, we interacted with Mark Adler, the author of Gzip, on StackOverflow. He gave us a silly answer. We digress. He suggests running already-compressed data through multiple compression stages.
Redundancy in Neuralink’s corpus exists at the bit-level, not the byte-level. 7Zip’s failure and Bzip’s success hinted towards this conclusion.
At bit-level redundancy, your best approach is increasing sparsity. This means, reducing the number of 1’s and increasing the number of 0’s in a binary dataset. We can’t cite this, just trust us bro. We took a gap year to build a data compression startup. We’ve gone so far down the rabbit hole that we can quote Mark Adler while the Neuralink engineers (obviously) can’t.
We have the Uniformity Measure - a replacement for Shannon Entropy personalized for the Neuralink corpus. We can measure each file’s distance from the uniform distribution, and attempt to increase this distance. (Make the file less uniform aka Decreasing Uniformity)
Let’s Start Coding
In this section, we code a custom Neuralink compressor in 4 steps.
Compress all our files using Bzip2.
Measure each file’s uniformity.
Build a transform to move each file away from the uniform distribution.
Write a binary arithmetic coder to store our bits.
Quick Disclaimer
- This code runs on Ubuntu so I assume you have Bzip2 installed.
Step 1. Using C’s system() command to call Linux’s Bzip2 utility
We write a function called EncodeBzip. The function compresses each .wav file in the Neuralink corpus into a .bz2 file. The function also creates a new directory called ‘Output’ to store the .bz2 files.

Now, we have a folder filled with .bz2 files.

Step 2 : Measuring each file’s uniformity
Next, we write a custom function to measure our file’s uniformity. Earlier, we mentioned Neuralink’s redundancy existed at the bit-level. Therefore, we shall measure uniformity at the bit-level. We’ll sum the number of 1’s in each byte. Then we’ll divide by 8 times the number of bytes. (There are 8 bits in a byte)

Were our files uniformly-distributed then the number of 1’s and 0’s would be equal. Thus, the uniformity measure of a uniformly-distributed binary sample is 0.5.
In our case, we observe the .bz2 files have a uniformity measure close to 0.5. Here are some uniformity measures taken for arbitrary files.
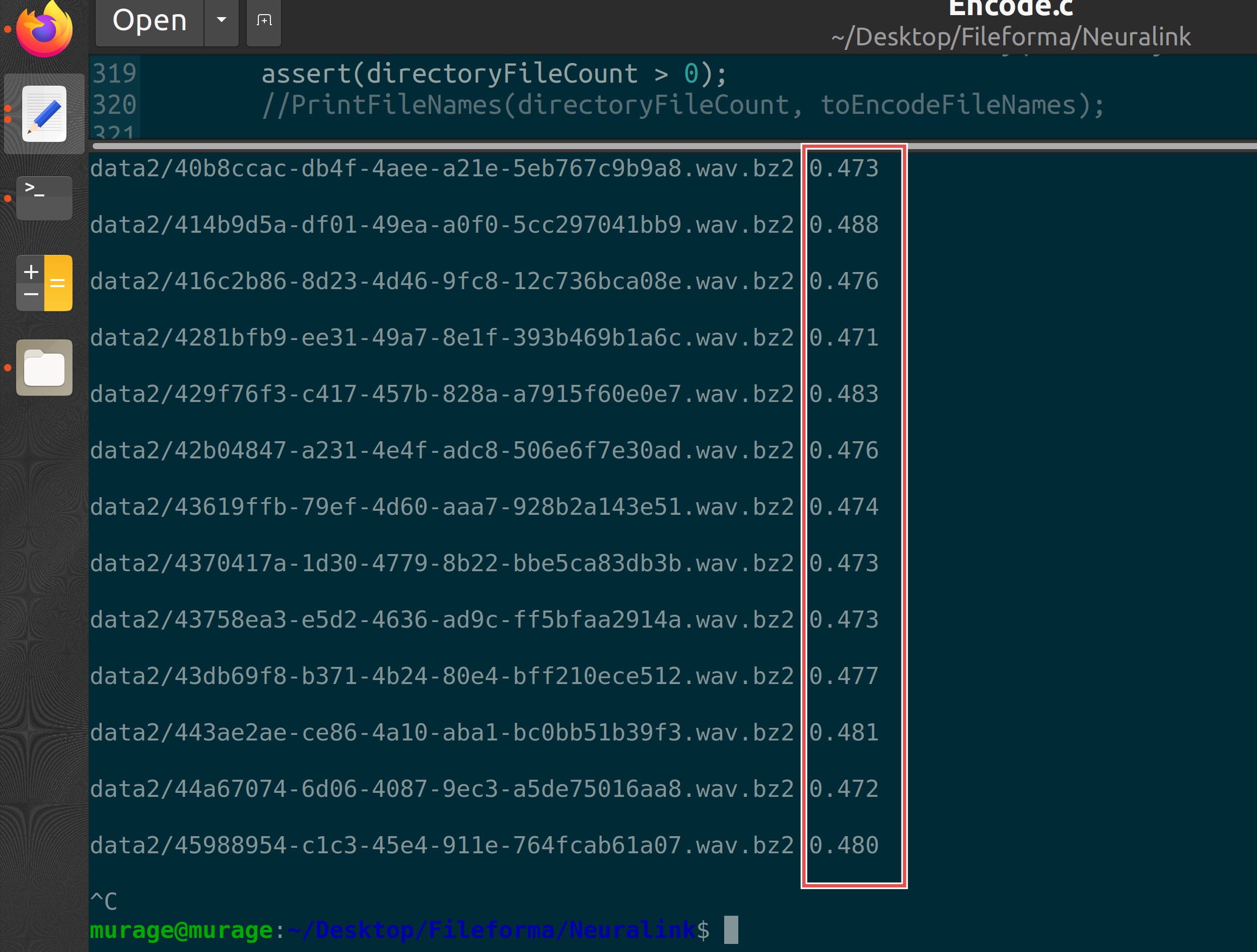
Step 3 : A simple transform to decrease uniformity
We write a recursive function called MakeLessUniform. The function counts the number of 1’s in different subsets of our data. If there are more 1’s than 0’s in a particular subset, then the function inverts the bits in that subset.

After performing our transform, we observe that our uniformity values decrease. We achieve our goal. Red is initial uniformity. Green is uniformity after performing our transform. Not all values change. We’ll optimize for that in our next post.

Step 4. Writing a binary arithmetic coder
Finally, we write a binary arithmetic coder to store our data. There are infinite ways to write a binary arithmetic coder. This Encode implementation is my favorite. You don’t worry about overflow bits and we experience zero floating point divisions - it’s all integer multiplications and bit shifts. The function parameters are a bit and the bit’s probability.

Results
First, we compare folder size. Our transform(Zip + Uniformity) outperforms Zip by 107084 bytes.

Next, we compare average file size. Our transform(Zip + Uniformity) outperforms Zip by 144 bytes on average.
Finally, we see our simple transform takes on average 0.016 seconds to execute.

Performance Optimizations
We memory map our files.
Our initial implementation worked on subsets of bits. This implementation manipulates subsets of bytes.
We use one lookup table to invert bits. We use a second lookup table to count set bits in each byte.
Our binary arithmetic coder uses bitshifts and multiplications - no floating point divisions. Furthermore, we avoid overflows compared to other implementations.
Final Note
We built our own entropy measure, then saved ~100 kB with a transform that took less than 0.02 seconds to run. This research project ran from May 24th to July 2nd24th. I built this during my nights and weekends(I have a day job). I wonder what more I could do if this were my fulltime job.
Thanks to buildspace.